第3章 第5节 涌现能力(二)-为什么会涌现
第3章 第5节 涌现能力(二)-为什么会涌现
阅读指南
上篇通过具体的例子,让你直观感受了涌现能力的震撼:算术、逻辑推理、代码生成、翻译、常识推理等能力,在大模型中"突然出现"。
中篇将深入探讨:
- 涌现的机制:为什么会产生涌现?
- Scaling Laws:一个让"赌"涌现变得可预测的数学定律
- 这对AI发展意味着什么?
下篇将讨论涌现的局限性、不可预测性,以及哲学思考。
5.1 涌现曲线
研究者们绘制了能力与模型规模的曲线,发现了一个惊人的模式。
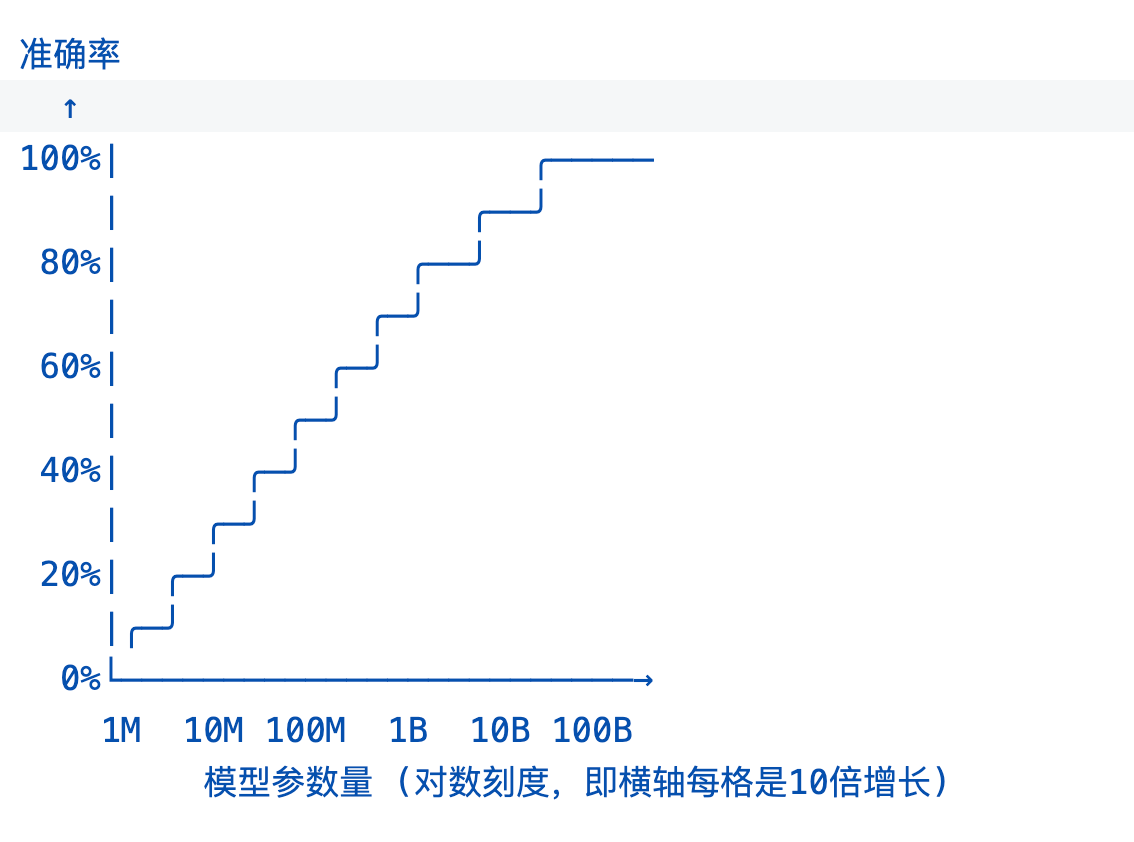
上图表明:**
- 存在阈值:
- 算术能力:大约在130亿参数左右涌现
- 复杂推理:大约在500-1000亿参数涌现
- 代码能力:大约在100-300亿参数涌现
- 不同能力的阈值不同:
简单任务先涌现,复杂任务后涌现- 涌现是突然的:
不是平滑增长,而是有一个"拐点"
5.2 为什么会涌现
这是最令人着迷,也最令人不安的部分:我们不完全理解涌现为什么发生。
有几个理论假说:
假说1:隐式学习组合能力
模型学到了很多"原子能力",当规模够大时,这些能力可以组合起来,产生新的"复合能力"。
例子:算术能力的涌现
模型可能分别学到了:
- 能力A:识别数字符号
- 能力B:理解"加"这个词的语义
- 能力C:数字大小的概念
- 能力D:数值操作的模式
小模型:每个能力都很弱,无法组合
大模型:每个能力都够强,可以组合 → 涌现出"算术"
假说2:跨越理解阈值
某些任务需要对概念有"足够深"的理解,达不到这个深度,就完全做不了。
例子:逻辑推理
需要:
- 理解"所有"的含义(全称量词)
- 理解"因为。..所以。.."的逻辑关系
- 追踪多个命题之间的关系
如果理解深度只有50%:
可能看起来"理解了",但推理时就错如果理解深度达到85%:
突然能够正确推理了这个"85%"就是阈值
小模型达不到阈值,大模型跨越了阈值,所以能力"涌现"。
假说3:记忆容量达到临界点
某些任务需要记住很多模式和例子,当记忆容量不够时,完全学不会。
例子:代码生成
训练数据中有数百万个代码片段,涵盖:
- 各种编程范式
- 各种语法结构
- 各种算法模式
- ...
小模型:记忆容量有限,只能记住一小部分模式
→ 遇到新问题,无法找到合适的模式 → 失败大模型:记忆容量大,能记住大部分模式
→ 遇到新问题,能找到相似的模式并适配 → 成功
假说4:涌现可能是幻觉
一些研究者认为,"涌现"可能部分是我们"测量方式"造成的幻觉。
论点:
如果我们用"准确率"(0或1)来衡量,会看到"突然涌现"
如果我们用更细粒度的指标(比如"部分正确度"),可能看到的是平滑增长例子:
小模型:"23 + 47 = 60" ← 准确率0%,但其实已经学到了"加法"的概念,只是算错了
大模型:"23 + 47 = 70" ← 准确率100%如果用"是否理解加法的概念"来衡量,小模型可能已经部分理解了,
而不是"完全不会" → "突然会了"
这个观点有一定道理,但不能完全解释所有的涌现现象。
但真相可能是以上几个因素的综合:
- 某些能力确实是组合的
- 某些任务确实有理解阈值
- 某些涌现可能被我们的测量方式夸大了
无论原因是什么,大模型确实展现出了小模型没有的能力。
5.3 涌现的启示
涌现现象给了我们一个深刻的启示:
在深度学习中,规模不仅仅带来量的提升,还可能带来质的飞跃。
这被研究者们半开玩笑地总结为:大力出奇迹。这意味着什么?
启示1:不要低估规模的力量
传统思维:
"如果小模型做不好某个任务,那可能这个任务不适合这种方法"涌现思维:
"如果小模型做不好,可能只是模型还不够大。
继续扩大,可能会突然就做好了。"
启示2:能力可能"潜伏"在小模型中
小模型可能已经学到了某个能力的"雏形",
只是还不足以表现出来。当规模增大,这些"雏形"成熟了,能力就涌现了。
启示3:我们可能还没有触及"天花板"
GPT-3 (1750亿参数)涌现了很多能力
GPT-4 (参数未公开,可能5000-10000亿)涌现了更多能力如果继续扩大到1万亿、10万亿参数,
可能还会涌现出我们现在完全想不到的能力。
但这也带来了一个问题。
5.4 令人不安的一面
涌现能力虽然令人惊叹,但也带来了一个问题:
我们无法预测哪些能力会涌现。
在训练GPT-3之前,OpenAI的研究者们并不知道它会涌现出算术能力、代码能力、多语言翻译能力。..
这些能力的出现,是惊喜,但也可能是惊吓。
- 好的能力会涌现,坏的能力也可能涌现
好的涌现:
- 算术推理
- 代码生成
- 逻辑推理
坏的涌现可能:
- 生成更有说服力的虚假信息
- 学会欺骗(在某些情况下)
- 发现系统的安全漏洞并利用
- 我们无法提前测试
因为涌现是突然的,我们无法在小模型上"预见"大模型会有什么能力。
如果训练一个超大模型,在训练完成之前,我们不知道它会涌现出什么能力。
- 对齐变得更困难
我们在RLHF中对齐的,是我们"已知"的能力和行为。
但如果模型涌现出新的能力,这些能力可能没有被充分对齐。
GPT-3训练完成后,研究者们发现它能生成代码。但RLHF主要针对的是回答问题、拒绝有害请求等。对于生成代码的行为规范,可能没有充分对齐。
这是AI安全研究的一个核心关切。
5.5 Scaling Laws
虽然我们不能预测哪些能力会在什么时候涌现,但研究者们发现,模型的性能与规模之间,存在某种数学关系。
这被称为"Scaling Laws"(缩放法则)。什么是Scaling Laws?
Scaling Laws,直译是"扩展定律"或"缩放定律",指的是:当你改变系统的规模时,性能如何变化的规律。
在AI的语境里,具体指:
- Scaling = 扩大规模(更多参数、更多数据、更多算力)
- Laws = 定律(可预测的数学关系)
简单说:Scaling Laws告诉我们,模型越大,效果会按照什么规律变好。
2020年,OpenAI的研究人员发表了一篇论文,震动了整个AI界。
他们发现:模型性能与规模之间,存在可预测的数学关系。
这不是说"模型大一点,性能好一点"这种模糊的直觉,而是一个精确的幂律公式:
L(N)∝N−αL(N) \propto N^{-\alpha}
在此之前,大家都知道"模型越大,效果越好",但不知道:
- 大多少才有用?
- 效果会好多少?
- 值不值得投入更多资源?
而Scaling Laws给出了答案:性能提升是可以预测的。
让我给你一些直观的数字:
参数量增加10倍 → Loss降低约1.2倍
参数量增加100倍 → Loss降低约2.0倍
参数量增加1000倍 → Loss降低约3.4倍
这意味着:
- 投入越来越大(参数量成倍增长)
- 但收益越来越小(Loss的绝对下降量递减)
既然收益越来越小,为什么还要继续耗费巨资增加参数量?
答案是人们期待大模型有新的能力能够涌现。
但还是有问题。
我们之前讨论过,涌现是不可预知的,那这样投入是否值得?
Scaling Laws给出了答案。
它的价值在于,让这个对能力涌现的赌注变得安全了:
可预测的部分:
Loss会按照公式稳定下降
→ 即使不涌现,性能也会提升(只是提升有限)不可预测的部分:
某个Loss阈值可能触发涌现
→ 一旦涌现,能力会质变飞跃而历史数据显示,Loss降到某些关键点时,涌现现象反复出现。
Scaling Laws不能保证涌现,但能保证你在朝着涌现的方向前进。用对比说明:
在Scaling Laws之前(2020年前):
"我想造个更大的模型"
"会更好吗?" → 不知道
"好多少?" → 不知道
"值得投入吗?" → 不知道
这是纯粹的赌博
在Scaling Laws之后(2020年后):
"我想把模型扩大100倍"
"会更好吗?" → 确定会,Loss会降低2倍
"会涌现新能力吗?" → 不确定,但历史上都发生了
"最坏情况?" → Loss降2倍,性能稳定提升
"最好情况?" → 触发涌现,能力质变
这是有保底的风险投资
这就是为什么OpenAI敢"赌"GPT-3:
根据Scaling Laws计算:
GPT-3的Loss会比GPT-2降低约30%保底收益:性能稳定提升30%
期望收益:可能触发涌现(基于GPT-2的观察)
实际结果:不仅性能提升了,还涌现了代码、算术等能力
他们赌的不是"会不会涌现",而是"Loss降低后,涌现的概率有多大"。
这就是为什么从2018到2023,我们看到了GPT参数量在疯狂增长:
2018年 GPT-1: 117M参数 (基准线)
2019年 GPT-2: 1.5B参数 ← 增长13倍
2020年 GPT-3: 175B参数 ← 增长117倍
2023年 GPT-4: 未公开 ← 规模进一步增长
2025年 GPT-5: 未公开 ← 已发布
每一步,都是对Scaling Laws的验证。每一步,都带来了能力的跃升。
这个Scaling Law会一直有效吗?还是在某个点会失效?
如果一直有效:
那么理论上,只要资源足够,我们就能造出越来越强大的AI,直到…… 直到什么? AGI(通用人工智能)? 超越人类的智能?
如果会失效:
失效点在哪里? 是因为数据不够了? 还是因为这个范式本身到达了极限?
目前没人知道答案。
我们只能观察、实验,然后谨慎地向前。
但有一点是确定的:Scaling Laws给了整个AI领域一个清晰的方向——让模型变大,是一条可预测、可验证的通往更强智能的道路。
5.6 下节预告
Scaling Laws告诉了我们"让模型变大会怎样",但它没有回答一个问题:
是不是所有能力都会通过扩大规模涌现出来?
有没有什么能力是永远无法涌现的?
涌现的边界在哪里?
下篇将探讨涌现的边界,以及一些有趣的背后故事。
5.7 ■ 学点英语
| 中文 | English | 音标 | 说明 |
|---|---|---|---|
| 规模法则 | Scaling Laws | /ˈskeɪlɪŋ lɔːz/ | 模型性能与规模之间的幂律关系规律 |
| 幂律 | Power Law | /ˈpaʊə(r) lɔː/ | 两个变量间成幂指数关系的函数形式 |
| 参数量 | Parameter Count | /pəˈræmɪtə(r) kaʊnt/ | 模型中可学习权重的总数,衡量模型规模 |
| 算力 | Compute | /kəmˈpjuːt/ | 训练所消耗的浮点运算量,通常以 FLOPs 计 |
| 损失 | Loss | /lɒs/ | 模型预测与真实值之间的误差度量 |
| 非线性 | Non-linearity | /ˌnɒn lɪnɪˈærəti/ | 输入与输出不成比例变化的关系,是涌现的数学特征 |
| 拐点 | Inflection Point | /ɪnˈflekʃn pɔɪnt/ | 曲线凹凸性转变之处,能力跃迁常在此发生 |
| 外推 | Extrapolation | /ɪkˌstræpəˈleɪʃn/ | 从已知范围向外预测未知范围的推理 |